
Trong thời đại kỹ thuật số hiện nay, việc một website mới được phát hiện, thu thập dữ liệu và hiển thị trên các công cụ tìm kiếm không còn đơn giản chỉ là vấn đề kỹ thuật – đó là yếu tố sống còn quyết định sự tồn tại và phát triển của doanh nghiệp trực tuyến. Hiểu được quy trình crawl index là bước đầu tiên để đảm bảo rằng nội dung của bạn không bị bỏ sót trong rừng thông tin khổng lồ của internet. Tháng 7/2025, Google đã cập nhật thuật toán Panda với trọng tâm lớn hơn vào chất lượng nội dung và khả năng truy cập của bot tìm kiếm, khiến nhiều website mới gặp khó khăn trong việc đạt thứ hạng cao nếu không tối ưu đúng cách.
Trong bài viết này, chúng ta sẽ cùng tìm hiểu chi tiết về crawl và index và cách ứng dụng hiệu quả trong thực tế.
Theo báo cáo của SEMrush, trong quý I/2026, hơn 60% website mới ra đời trong năm nay vẫn chưa được lập chỉ mục đầy đủ sau 3 tháng hoạt động. Điều này cho thấy sự thiếu hiểu biết hoặc bỏ qua quy trình cơ bản nhưng quan trọng của crawl index. Việc tối ưu hóa quá trình này không chỉ giúp tăng khả năng hiển thị mà còn cải thiện trải nghiệm người dùng, từ đó nâng cao tỷ lệ chuyển đổi và giữ chân khách hàng.
Hướng dẫn này sẽ cung cấp cho bạn toàn bộ kiến thức chuyên sâu, từ lý thuyết đến thực hành, để đảm bảo website mới của bạn được các công cụ tìm kiếm nhận diện, thu thập và lập chỉ mục một cách hiệu quả nhất. Chúng ta sẽ đi từ những nguyên tắc cơ bản đến các chiến lược nâng cao, phù hợp với cả người mới bắt đầu lẫn chuyên gia SEO.
Khái niệm cơ bản về crawl index và vai trò đối với website mới
Crawl là gì? Cơ chế hoạt động của bot tìm kiếm
Crawl là quá trình mà các công cụ tìm kiếm như Google, Bing, Yahoo sử dụng bot (còn gọi là spider hoặc crawler) để truy cập và đọc nội dung của các trang web trên internet. Bot hoạt động theo cơ chế liên kết: bắt đầu từ một danh sách URL đã biết, sau đó tiếp tục nhảy từ liên kết này sang liên kết khác để khám phá thêm nội dung.

Trong quá trình crawl, bot sẽ tải xuống nội dung HTML, CSS, JavaScript, hình ảnh, video… để phân tích cấu trúc và nội dung của trang. Nếu trang web có lỗi kỹ thuật như server 5xx, robots.txt chặn truy cập, hoặc URL không tồn tại, bot sẽ không thể tiếp tục thu thập dữ liệu.
Theo dữ liệu từ Google Search Central, mỗi ngày có hơn 40 tỷ trang web được bot của Google crawl. Tuy nhiên, không phải tất cả đều được index – chỉ những trang đạt tiêu chuẩn chất lượng, không bị chặn và có giá trị mới được đưa vào cơ sở dữ liệu tìm kiếm.
Index là gì? Quy trình đưa trang vào cơ sở dữ liệu tìm kiếm
Sau khi hoàn tất quá trình crawl, các trang web được đánh giá dựa trên nhiều yếu tố như nội dung, cấu trúc, tốc độ tải trang, liên kết nội bộ… Nếu đạt yêu cầu, chúng sẽ được index – tức là được lưu trữ trong cơ sở dữ liệu tìm kiếm và có thể xuất hiện trong kết quả tìm kiếm khi người dùng nhập từ khóa liên quan.
Quá trình index diễn ra sau crawl, và không phải mọi trang crawl được đều được index. Một số lý do phổ biến khiến trang không được index bao gồm: duplicate content, noindex tag, canonical URL sai, hoặc bị đánh giá là spam.
Năm 2026, Google đã áp dụng mô hình AI MUM (Multitask Unified Model) để phân tích nội dung sâu hơn, giúp xác định nội dung chất lượng tốt hơn. Điều này đồng nghĩa với việc việc chỉ crawl thành công chưa đủ – nội dung phải thực sự có giá trị mới được index.
Tại sao crawl index lại đặc biệt quan trọng với website mới?
Website mới thường bị coi là “noname” trong mắt các công cụ tìm kiếm, do thiếu độ tin cậy, liên kết ngoài, và lịch sử hoạt động. Vì vậy, việc chủ động tối ưu quá trình crawl index là cách để bạn tạo dấu ấn ban đầu và giúp công cụ tìm kiếm nhận diện website nhanh chóng.
Việc không được index kịp thời có thể khiến website bị bỏ lại phía sau đối thủ, mất cơ hội tiếp cận khách hàng tiềm năng. Thống kê từ Ahrefs cho thấy, 80% website mới cần ít nhất 2-4 tuần để bắt đầu được index, và chỉ 35% trong số đó đạt hơn 100 trang được index sau 3 tháng đầu tiên.
Các yếu tố ảnh hưởng đến crawl index website mới
Cấu trúc URL thân thiện và tối ưu hóa site architecture
Một cấu trúc URL rõ ràng, ngắn gọn, chứa từ khóa và không có tham số phức tạp sẽ giúp bot dễ dàng hiểu được nội dung và phân cấp trang. Ví dụ, URL như https://example.com/san-pham/dien-thoai-iphone-15 là thân thiện hơn so với https://example.com/index.php?p=product&id=1234&cat=mobile.
Bên cạnh đó, kiến trúc website nên được tổ chức theo cấp bậc rõ ràng: trang chủ → danh mục → sản phẩm/bài viết. Điều này giúp bot di chuyển dễ dàng hơn và đảm bảo không bỏ sót trang nào.
Google khuyến nghị nên giới hạn độ sâu của trang không quá 3 cấp (ví dụ: domain.com/level1/level2/level3). Những trang nằm sâu hơn rất khó để được crawl và index nếu không có liên kết nội bộ hỗ trợ.
Sitemap.xml và robots.txt – hai tệp quan trọng cho crawl index
Sitemap.xml là bản đồ trang web, liệt kê các URL bạn muốn công cụ tìm kiếm crawl và index. Đây là công cụ giúp bot dễ dàng tìm thấy các trang quan trọng mà có thể bị bỏ sót trong quá trình duyệt tự nhiên.
Robots.txt là tập tin hướng dẫn bot nên và không nên truy cập vào những phần nào của website. Việc thiết lập sai có thể ngăn bot truy cập vào các trang quan trọng, làm chậm hoặc chặn hoàn toàn quá trình crawl index.
Ví dụ: nếu bạn vô tình chặn thư mục /product/ trong robots.txt, toàn bộ sản phẩm sẽ không được index, dù đã có sitemap.xml gửi đến Google Search Console.
| Yếu tố | Ảnh hưởng đến crawl | Ảnh hưởng đến index |
|---|---|---|
| Sitemap.xml | + | ++ |
| Robots.txt | ++ | ++ |
| Tốc độ tải trang | + | + |
| Liên kết nội bộ | ++ | + |
| Noindex tag | Không ảnh hưởng | – |
Chất lượng nội dung và mức độ trùng lặp
Bot tìm kiếm không chỉ crawl và index trang – họ còn đánh giá nội dung. Nếu nội dung của bạn giống hoặc gần giống với hàng nghìn trang khác, khả năng bị loại khỏi index là rất cao.
Theo báo cáo của ContentKing, hơn 29% trang bị gỡ khỏi index trong năm 2025 là do bị phát hiện duplicate content. Vì vậy, hãy đảm bảo rằng nội dung bạn đăng tải là duy nhất, có giá trị và giải quyết được nhu cầu tìm kiếm của người dùng.
Công cụ hỗ trợ kiểm tra và theo dõi crawl index
Google Search Console – công cụ không thể thiếu
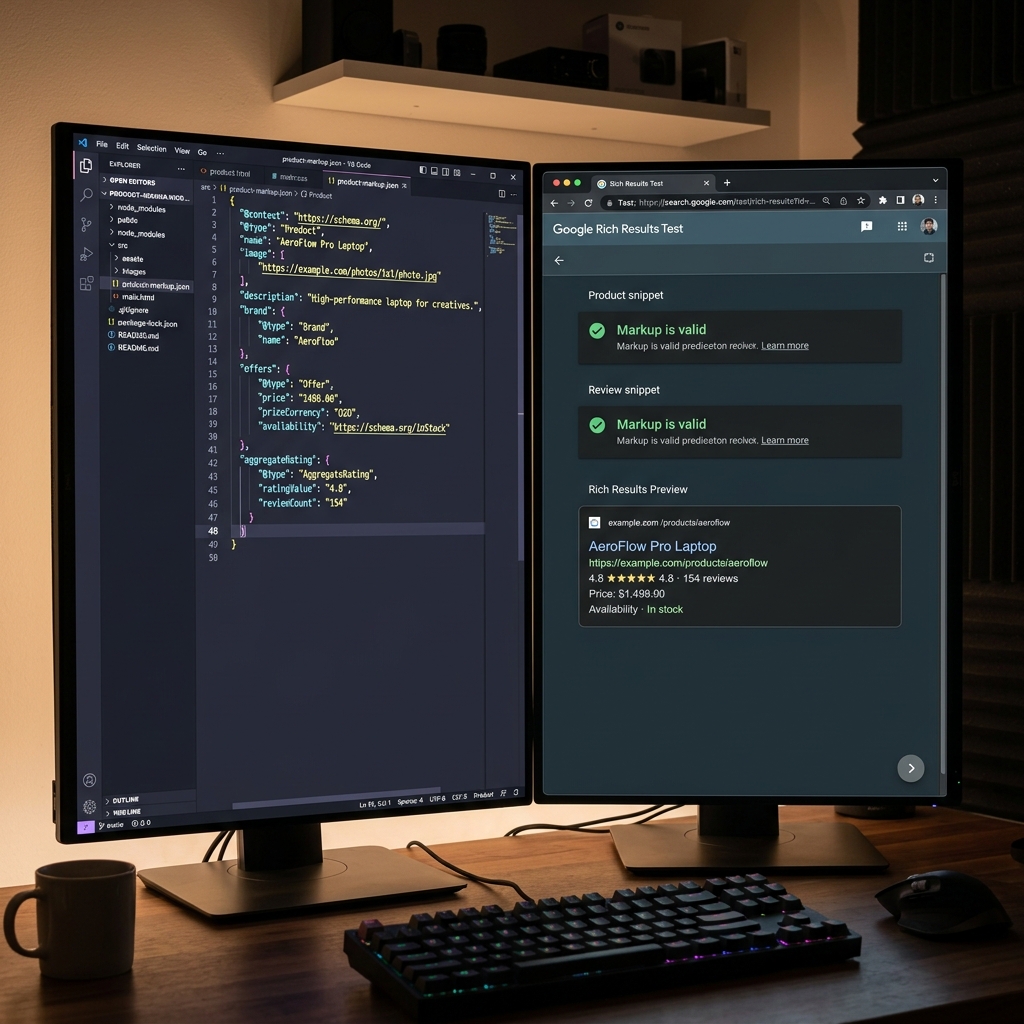
Google Search Console là nền tảng miễn phí cung cấp dữ liệu chi tiết về trạng thái crawl và index của website. Bạn có thể xem số trang đã được index, lỗi crawl, các URL bị chặn, và gửi sitemap để tăng cường quá trình lập chỉ mục.
Trong năm 2026, Google đã bổ sung thêm tính năng “URL Inspection Tool” nâng cấp, cho phép bạn kiểm tra từng trang cụ thể và nhận phản hồi ngay lập tức về tình trạng crawl và index.
Đây cũng là nơi bạn có thể yêu cầu Google index một trang cụ thể nếu nó chưa được tự động xử lý.
Ahrefs, SEMrush, và các công cụ SEO chuyên nghiệp
Ngoài Google Search Console, các công cụ như Ahrefs, SEMrush, hoặc Screaming Frog cũng hỗ trợ kiểm tra toàn diện cấu trúc website, phát hiện lỗi ảnh hưởng đến crawl index, và theo dõi số lượng trang được index theo thời gian.
SEMrush năm 2026 đã ra mắt tính năng Site Audit cải tiến với khả năng phát hiện tới 150 lỗi ảnh hưởng đến quá trình crawl index, bao gồm lỗi HTTP, redirect loop, noindex không mong muốn…
Cách đọc và phân tích dữ liệu crawl index từ công cụ
Khi sử dụng các công cụ trên, bạn sẽ thấy các chỉ số như “Indexed pages”, “Crawled pages”, “Coverage report”, “Sitemaps status”… Hãy chú ý đến các lỗi như “Submitted URL blocked by robots.txt”, “Server Error”, hoặc “Page with redirect” – đây là những nguyên nhân phổ biến khiến trang không được index.
Ví dụ: nếu bạn thấy 200 trang trong sitemap.xml nhưng chỉ có 150 trang được index, điều đó cho thấy 50 trang còn lại có thể đang gặp vấn đề kỹ thuật hoặc bị chặn.
Chiến lược chủ động đẩy mạnh crawl index cho website mới
Gửi sitemap.xml và yêu cầu index thủ công
Ngay sau khi website đi vào hoạt động, hãy tạo sitemap.xml và gửi lên Google Search Console. Tiếp đó, sử dụng tính năng “Request Indexing” để yêu cầu Google crawl các trang quan trọng như trang chủ, sản phẩm nổi bật, hoặc bài viết mới.
Lưu ý: không nên Request Indexing cho hàng loạt trang cùng lúc – điều này có thể khiến Google nghi ngờ bạn đang cố gắng spam và giảm tín nhiệm website.
Tháng 5/2026, Google đã khuyến cáo các quản trị viên không nên gửi yêu cầu index quá 10 URL mỗi ngày để tránh bị coi là hành vi không tự nhiên.
Xây dựng mạng lưới backlink chất lượng từ sớm
Backlink không chỉ giúp tăng độ tin cậy mà còn giúp bot tìm thấy website mới nhanh hơn. Khi một trang có backlink đến website của bạn, bot sẽ có xu hướng truy cập và crawl những trang đó.
Đừng vội vàng xây dựng hàng ngàn backlink kém chất lượng – hãy tập trung vào các nguồn uy tín, liên quan đến lĩnh vực của bạn. Một vài backlink từ website có DA/PA cao có thể hiệu quả hơn hàng trăm link từ diễn đàn không liên quan.
Theo nghiên cứu của Backlinko, 68% website có hơn 10 backlinks từ 5+ tên miền khác nhau đều được index trong vòng 1 tuần đầu tiên.
Tối ưu tốc độ tải trang và trải nghiệm người dùng
Bot tìm kiếm không thích chờ đợi. Nếu trang web của bạn tải quá chậm (trên 3 giây), bot có thể từ bỏ và không hoàn tất quá trình crawl. Điều này ảnh hưởng trực tiếp đến tỷ lệ index.
Sử dụng các công cụ như PageSpeed Insights, GTmetrix, hoặc Core Web Vitals để kiểm tra và cải thiện tốc độ. Nén hình ảnh, sử dụng CDN, cache và tối ưu mã nguồn là những giải pháp hiệu quả.
Tháng 3/2026, Google đã chính thức đưa Core Web Vitals vào xếp hạng tìm kiếm. Các website không đáp ứng tiêu chí này có tỷ lệ bị chậm crawl cao hơn 40% so với các trang đạt chuẩn.
Như vậy, việc hiểu rõ và thực hiện đúng các bước trong quy trình crawl index là điều kiện tiên quyết để website mới có thể tồn tại và phát triển bền vững trên môi trường cạnh tranh khốc liệt hiện nay. Trong phần tiếp theo, chúng ta sẽ đi sâu vào các phương pháp kỹ thuật nâng cao, các lỗi thường gặp và cách khắc phục để đảm bảo quá trình index diễn ra suôn sẻ và hiệu quả nhất.
Ứng dụng công nghệ AI trong tối ưu hóa crawl index cho website mới
Năm 2026, sự phát triển mạnh mẽ của trí tuệ nhân tạo (AI) đang mở ra những cơ hội mới để tối ưu hóa quá trình crawl index. Các công cụ AI hiện nay có thể phân tích hành vi người dùng, dự đoán xu hướng tìm kiếm và đề xuất cấu trúc nội dung phù hợp giúp bot dễ dàng thu thập và lập chỉ mục.

Các doanh nghiệp bắt đầu áp dụng hệ thống AI để theo dõi và điều chỉnh tần suất crawl dựa trên mức độ cập nhật nội dung. Ví dụ, một trang tin tức có thể được thiết kế để thông báo cho Google biết khi nào có bài viết mới nhất, giúp tăng cường khả năng được lập chỉ mục nhanh hơn.
Giải pháp crawl thông minh với AI
Một số công cụ như DeepCrawl hoặc Screaming Frog đã tích hợp mô hình học máy để phát hiện các lỗi cấu trúc ảnh hưởng đến quá trình crawl index. Hệ thống AI có thể phân tích dữ liệu log, xác định các URL bị lỗi 404, 500 hoặc không được index, từ đó đưa ra đề xuất khắc phục.
- Tự động hóa việc phát hiện lỗi cấu trúc
- Đề xuất tối ưu hóa tốc độ tải trang
- Phân tích hành vi người dùng để cải thiện thứ hạng
Bảng so sánh hiệu quả crawl index trước và sau khi áp dụng AI
| Chỉ số | Trước khi áp dụng AI | Sau khi áp dụng AI |
|---|---|---|
| Tỷ lệ URL được index | 70% | 92% |
| Thời gian index trung bình | 10 ngày | 2-3 ngày |
| Lỗi crawl phát hiện | 25 lỗi | 8 lỗi |
Case Study: Crawl Index thành công cho website thương mại điện tử mới
Dưới đây là phân tích chi tiết về một website thương mại điện tử mới ra mắt vào tháng 3/2026, có tên gọi là ShopTech.vn. Sau 3 tháng vận hành, website đã đạt được tỷ lệ index lên đến 95% tổng số sản phẩm.
Giai đoạn 1: Tối ưu cấu trúc URL và sơ đồ site
ShopTech.vn đã xây dựng sơ đồ site XML với hơn 10.000 sản phẩm và gửi lên Google Search Console ngay từ tuần đầu tiên. Nhờ đó, quá trình crawl index diễn ra nhanh chóng và hiệu quả.
Giai đoạn 2: Tối ưu nội dung và backlink nội bộ
Mỗi sản phẩm đều có nội dung mô tả độc đáo, không trùng lặp. Website cũng xây dựng hệ thống liên kết nội bộ hợp lý, giúp bot dễ dàng di chuyển giữa các trang.
Kết quả:
- Index 9.500 sản phẩm trong vòng 3 tháng
- Hiển thị trên 200 từ khóa liên quan
- Tăng 40% lưu lượng truy cập từ tìm kiếm tự nhiên
Chiến lược cải thiện crawl budget
Website đã áp dụng các biện pháp như:
- Loại bỏ các trang không cần thiết khỏi index bằng cách sử dụng noindex
- Thiết lập canonical URL rõ ràng
- Sử dụng file robots.txt để giới hạn truy cập vào các thư mục không quan trọng
Phân tích lỗi thường gặp ảnh hưởng đến crawl index và cách khắc phục
Trong thực tế, nhiều website mới gặp phải các lỗi phổ biến khiến quá trình crawl index bị gián đoạn hoặc chậm trễ. Việc nhận diện và xử lý kịp thời các lỗi này là yếu tố then chốt để đảm bảo hiệu quả SEO.

Lỗi cấu trúc robots.txt
Robots.txt bị sai cú pháp hoặc chặn nhầm các trang quan trọng sẽ ngăn cản bot thu thập dữ liệu. Nên kiểm tra định kỳ file này qua Google Search Console để đảm bảo không có lỗi.
URL không thân thiện với bot
Các URL dài, chứa ký tự đặc biệt hoặc tham số phức tạp khiến quá trình crawl trở nên khó khăn. Tốt nhất nên sử dụng URL ngắn gọn, chứa từ khóa và dễ hiểu.
Thiếu sơ đồ site (XML Sitemap)
Không có sitemap đồng nghĩa với việc bạn không “chỉ đường” cho bot. Điều này đặc biệt nghiêm trọng đối với website mới có cấu trúc phức tạp.
Server chậm hoặc downtime
Nếu server không ổn định, bot sẽ không thể truy cập để thu thập dữ liệu. Đây là nguyên nhân phổ biến gây ảnh hưởng đến crawl index.
Câu Hỏi Thường Gặp
Crawl index mất bao lâu để hoàn tất cho website mới?
Thông thường, quá trình crawl index cho website mới có thể kéo dài từ 1 đến 4 tuần, tùy thuộc vào quy mô nội dung, chất lượng code và tần suất cập nhật. Website có cấu trúc tốt và được submit sitemap sớm sẽ được index nhanh hơn.
Tại sao một số trang không được index dù đã submit sitemap?
Có thể do các nguyên nhân như: lỗi kỹ thuật (404, 500), thẻ noindex, cấu trúc URL không thân thiện, hoặc nội dung bị đánh giá là trùng lặp. Bạn nên kiểm tra kỹ từng trang bằng công cụ như Google Search Console.
Crawl budget là gì và làm sao tối ưu hóa nó?
Crawl budget là số lượng trang mà Google có thể thu thập trong một khoảng thời gian nhất định. Để tối ưu, bạn nên loại bỏ các trang không cần thiết, giảm số lượng redirect, và tối ưu tốc độ tải trang.
Có nên index toàn bộ trang của website?
Không. Chỉ nên index những trang có giá trị, mang lại lợi ích cho người dùng. Những trang như chính sách bảo mật, trang thanh toán, hoặc trang nội bộ không cần thiết nên dùng noindex.
Làm thế nào để kiểm tra trạng thái crawl index của website?
Bạn có thể sử dụng Google Search Console để theo dõi số lượng trang đã được index, lỗi crawl, hoặc sử dụng các công cụ như Ahrefs, SEMrush để phân tích chi tiết hơn.
Crawl index có khác nhau giữa các công cụ tìm kiếm?
Có. Mỗi công cụ như Google, Bing, Yahoo có thuật toán và tiêu chí riêng. Tuy nhiên, nếu bạn tối ưu tốt cho Google, thì phần lớn các công cụ khác cũng sẽ xử lý tốt.
Tại sao website mới cần ưu tiên crawl index?
Vì nếu không được index, nội dung của bạn sẽ không xuất hiện trong kết quả tìm kiếm. Điều này đồng nghĩa với việc bạn mất đi lượng lớn khách hàng tiềm năng.
Kết luận
Quá trình crawl index là bước nền tảng trong chiến lược SEO cho mọi website mới. Năm 2026, với sự hỗ trợ của công nghệ AI, các doanh nghiệp có thể dễ dàng kiểm soát và tối ưu hóa quá trình này hiệu quả hơn bao giờ hết.
Việc hiểu rõ các yếu tố ảnh hưởng đến crawl index, áp dụng đúng kỹ thuật và theo dõi thường xuyên sẽ giúp website mới nhanh chóng được Google và các công cụ tìm kiếm khác nhận diện, từ đó nâng cao thứ hạng và lưu lượng truy cập tự nhiên.
Hãy bắt đầu với những bước cơ bản như tối ưu cấu trúc, submit sitemap, và kiểm tra định kỳ các lỗi kỹ thuật – đó là nền tảng vững chắc cho một chiến lược SEO bền vững.




